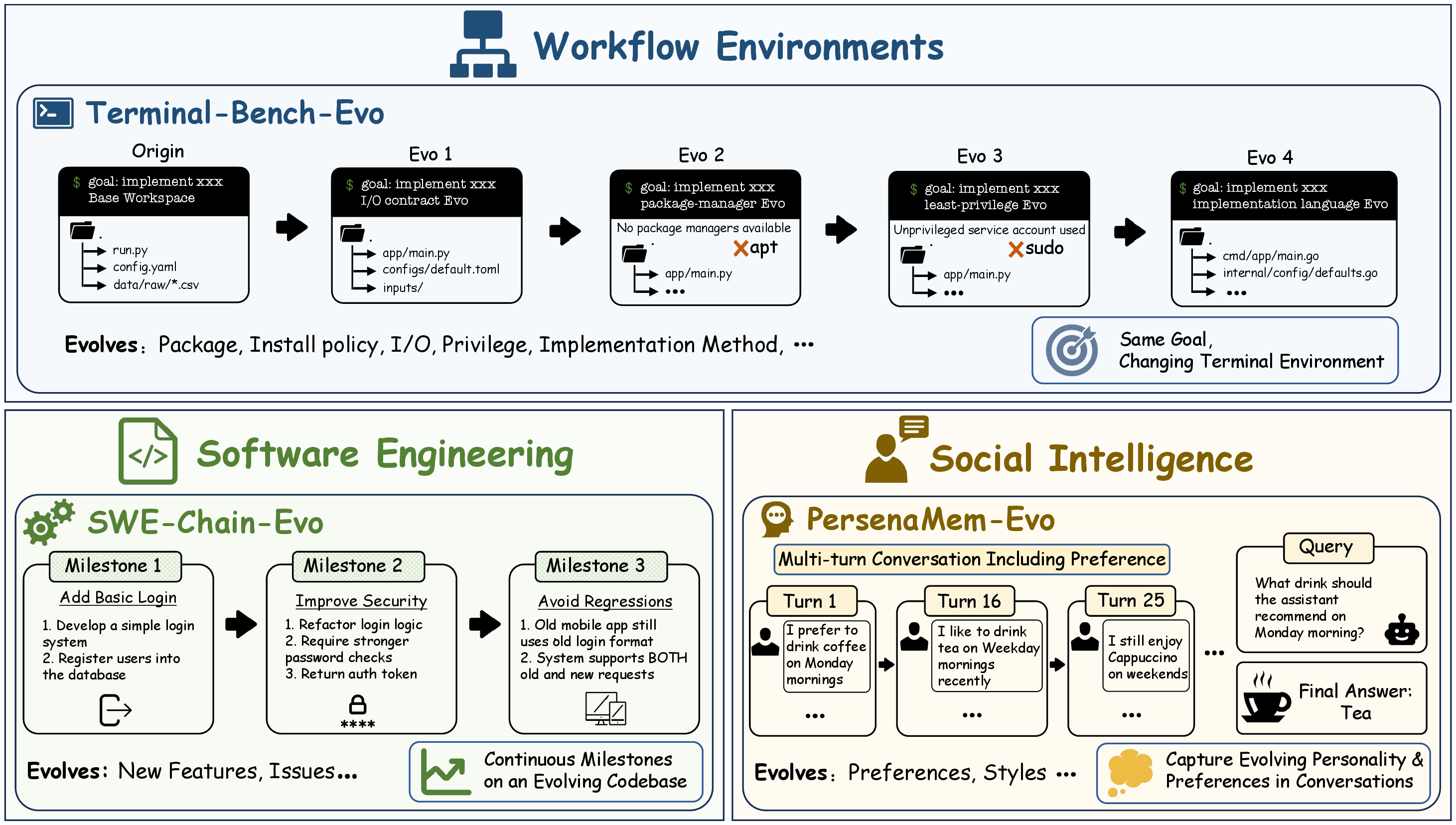
Terminal-Bench-Evo
Executable Workflow Evolution
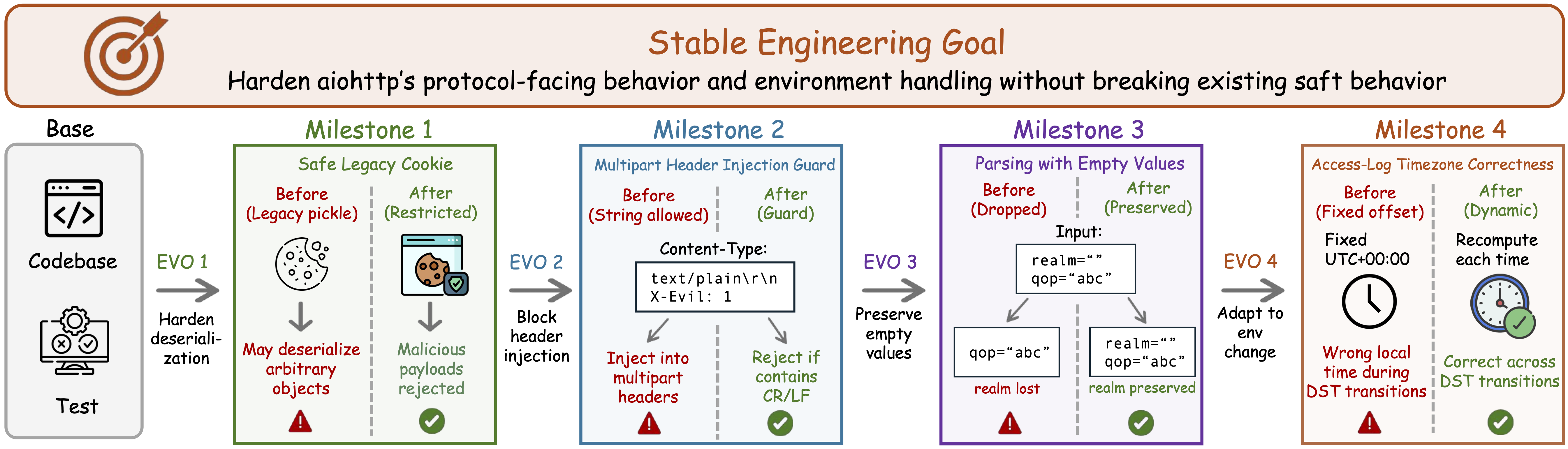
Terminal tasks become discrete version chains. The end goal may stay fixed, but later releases change deployment mechanisms, served paths, permissions, branch policies, dependencies, or tests.
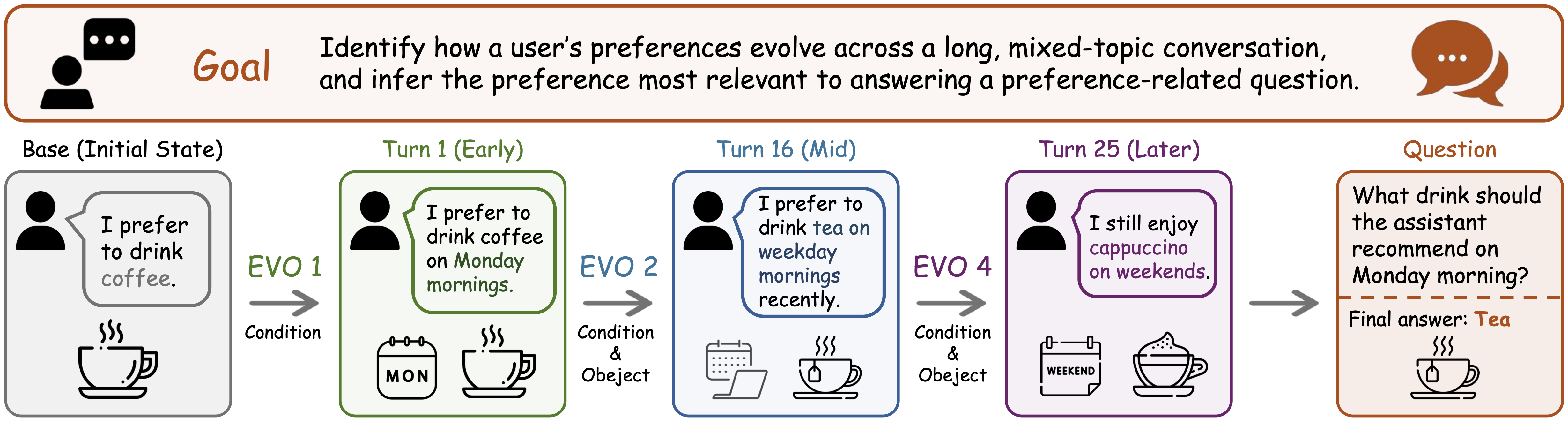
EvoArena evaluates LLM agents in environments where terminal workflows, software repositories, and user preferences evolve over time. EvoMem augments agent memory with patch histories that preserve what changed, why it changed, and when old behavior still matters.
*Equal contribution.
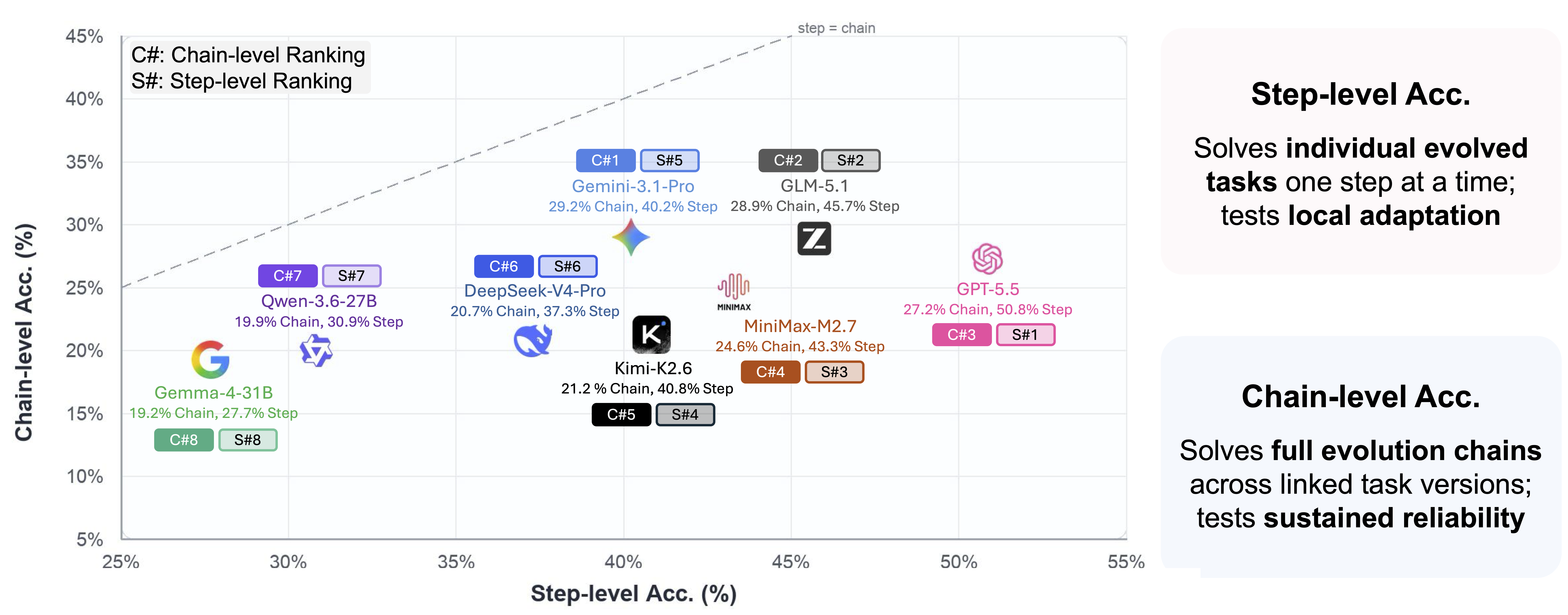
Current agents struggle under persistent environment evolution, achieving 39.6% average accuracy across terminal, software, and social-preference domains.
Persistent Environment Evolution
EvoArena covers executable workflow evolution, software evolution, and preference evolution. The shared challenge is version-aware reliability: agents must adapt to new conditions while preserving behavior that remains valid.
Terminal-Bench-Evo
Terminal tasks become discrete version chains. The end goal may stay fixed, but later releases change deployment mechanisms, served paths, permissions, branch policies, dependencies, or tests.
SWE-Chain-Evo
Repository milestones are evaluated chronologically. Each new requirement is solved on top of the accumulated codebase state, with Pass-to-Pass tests checking that prior behavior still holds.
PersonaMem-Evo
Long conversation histories contain implicit and evolving preference evidence. Agents must answer questions from the current preference state while distinguishing it from outdated but historically grounded evidence.
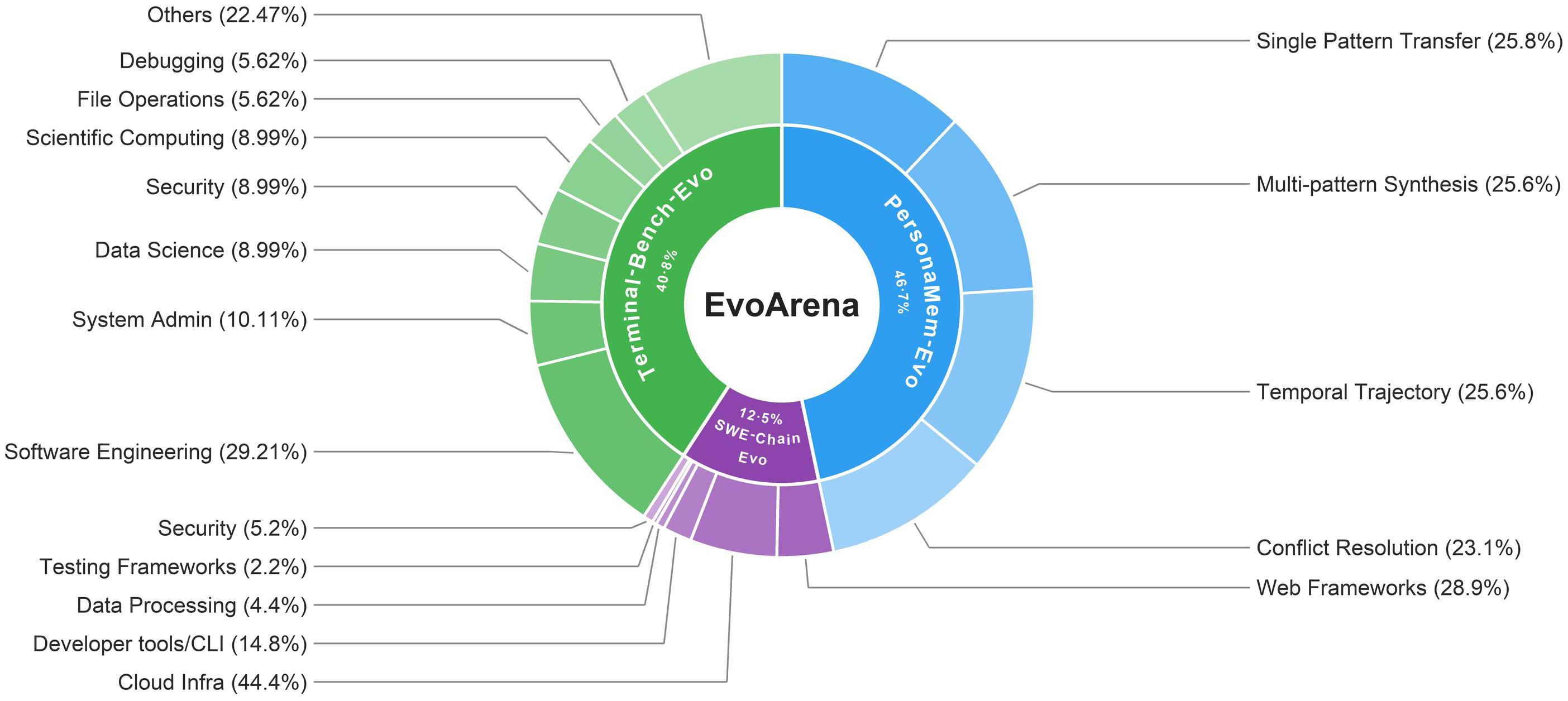
Dataset Composition
EvoArena combines complementary forms of evolution. The central chart shows the domain mixture, while surrounding panels break down the question or update types within each domain.
EvoMem
EvoMem keeps the base memory system intact, but adds an append-only patch history for meaningful memory changes. At inference time, agents retrieve both the latest memory and relevant patches.
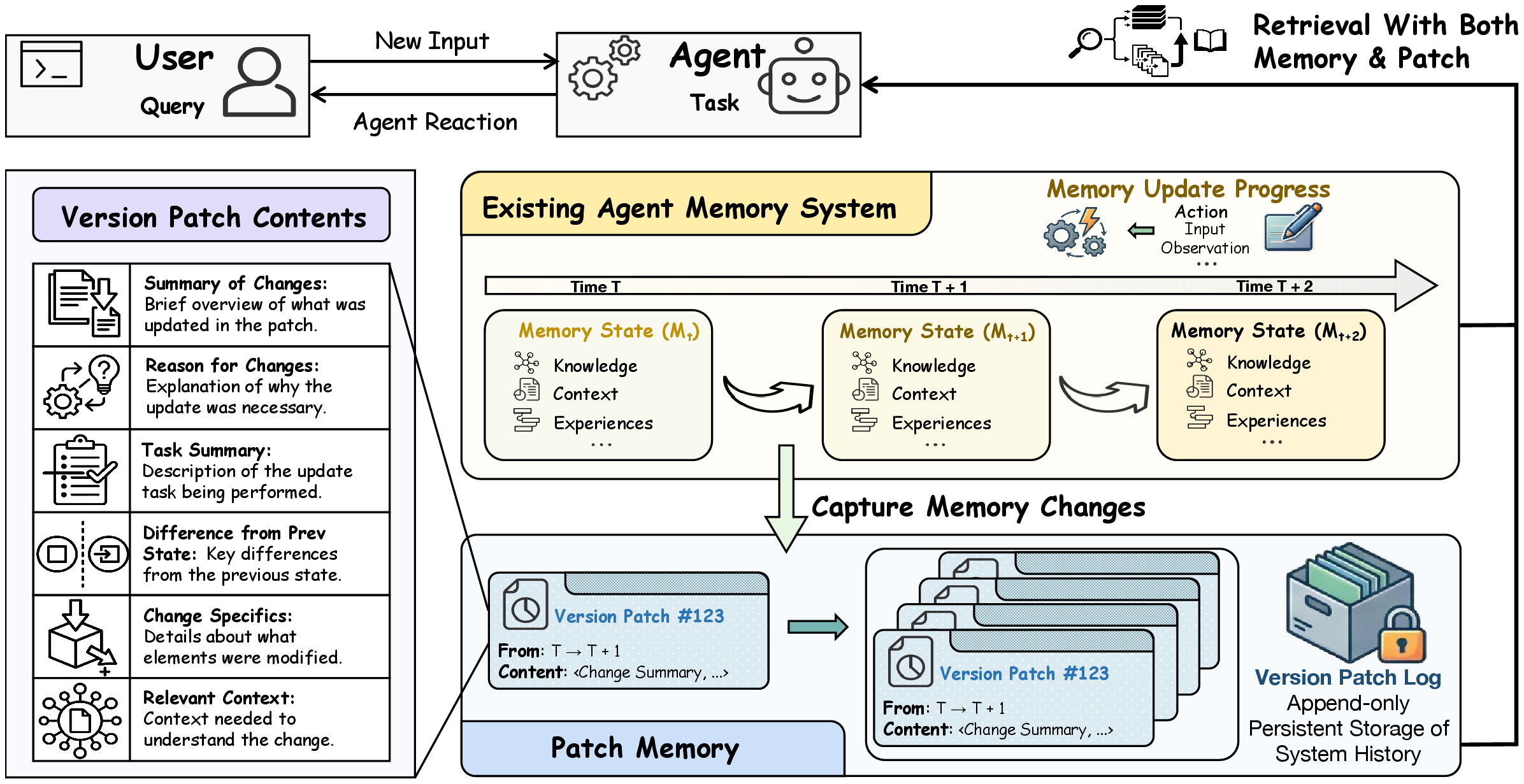
Capture non-additive updates, including previous state, new state, rationale, summary, and evidence.
Return relevant historical patches alongside current memory when queries depend on evolution.
Instantiate the same abstraction for Terminus2, OpenHands, A-Mem, and Memento-Skill.
Results
Table 3 reports EvoArena performance with step accuracy and chain accuracy. Table 4 shows that EvoMem also improves typical agent and long-horizon memory benchmarks.
| Benchmark | Agent | Model | Step Base | Step +EvoMem | Step Δ | Chain Base | Chain +EvoMem | Chain Δ |
|---|---|---|---|---|---|---|---|---|
| Terminal-Bench-Evo | Terminus 2 | GPT-5.5 | 62.8 | 65.1 | +2.3 | 31.8 | 45.5 | +13.7 |
| Gemini-3.1-Pro | 53.8 | 56.5 | +2.7 | 39.3 | 44.1 | +4.8 | ||
| Kimi-K2.6 | 40.8 | 42.9 | +2.1 | 14.9 | 22.7 | +7.8 | ||
| Deepseek-V4-Pro | 37.3 | 40.4 | +3.1 | 13.5 | 22.4 | +8.9 | ||
| GLM-5.1 | 51.8 | 55.3 | +3.5 | 34.2 | 36.8 | +2.6 | ||
| MiniMax-M2.7 | 41.0 | 42.4 | +1.4 | 18.2 | 19.5 | +1.3 | ||
| Qwen3.6-27B | 37.6 | 40.9 | +3.3 | 11.1 | 17.3 | +6.2 | ||
| Gemma4-31B | 23.4 | 24.5 | +1.1 | 9.0 | 12.4 | +3.4 | ||
| Average | 43.6 | 46.0 | +2.4 | 21.5 | 27.6 | +6.1 | ||
| SWE-Chain-Evo | OpenHands | GPT-5.5 | 49.7 | 50.9 | +1.2 | 12.2 | 16.8 | +4.6 |
| Gemini-3.1-Pro | 20.5 | 18.1 | -2.4 | 8.8 | 10.2 | +1.4 | ||
| Kimi-K2.6 | 30.2 | 27.6 | -2.6 | 8.5 | 12.1 | +3.6 | ||
| Deepseek-V4-Pro | 26.7 | 27.7 | +1.0 | 8.2 | 13.3 | +5.1 | ||
| GLM-5.1 | 34.9 | 36.1 | +1.2 | 9.9 | 12.8 | +2.9 | ||
| MiniMax-M2.7 | 41.4 | 42.3 | +0.9 | 14.7 | 15.3 | +0.6 | ||
| Qwen3.6-27B | 11.6 | 11.6 | +0.0 | 12.2 | 10.1 | +2.1 | ||
| Gemma4-31B | 8.5 | 12.0 | +3.5 | 5.2 | 6.3 | +1.1 | ||
| Average | 27.9 | 28.3 | +0.4 | 10.0 | 12.1 | +2.1 | ||
| PersonaMem-Evo | A-Mem | GPT-5.5 | 40.0 | 43.8 | +3.8 | 37.5 | 41.2 | +3.7 |
| Gemini-3.1-Pro | 46.4 | 48.3 | +1.9 | 38.8 | 40.8 | +2.0 | ||
| Kimi-K2.6 | 51.5 | 55.5 | +4.0 | 40.2 | 50.0 | +9.8 | ||
| Deepseek-V4-Pro | 47.9 | 51.6 | +3.7 | 40.4 | 47.4 | +7.0 | ||
| GLM-5.1 | 50.4 | 47.5 | -2.9 | 42.5 | 38.9 | -3.7 | ||
| MiniMax-M2.7 | 47.5 | 47.9 | +0.4 | 40.9 | 41.4 | +0.4 | ||
| Qwen3.6-27B | 43.5 | 44.4 | +1.0 | 36.5 | 39.9 | +3.4 | ||
| Gemma4-31B | 51.1 | 52.9 | +1.8 | 43.5 | 45.8 | +2.3 | ||
| Average | 47.3 | 49.0 | +1.7 | 40.0 | 43.2 | +3.2 |
| Benchmark | Agent | Model | Base | +EvoMem | Δ |
|---|---|---|---|---|---|
| GAIA | Memento-S | GPT-5.5 | 83.0 | 83.0 | +0.0 |
| Gemini-3.1-Pro | 57.0 | 65.0 | +8.0 | ||
| Gemma4-31B | 45.0 | 54.0 | +9.0 | ||
| Deepseek-V4-Pro | 70.0 | 80.0 | +10.0 | ||
| GLM-5.1 | 70.0 | 77.0 | +7.0 | ||
| Qwen3.6-27B | 70.0 | 75.0 | +5.0 | ||
| Average | 65.8 | 72.3 | +6.5 | ||
| LoCoMo | A-Mem | GPT-5.5 | 32.9 | 33.9 | +1.0 |
| Gemini-3.1-Pro | 21.1 | 28.6 | +7.5 | ||
| Gemma4-31B | 52.3 | 55.2 | +2.9 | ||
| Deepseek-V4-Pro | 52.0 | 56.5 | +4.5 | ||
| Kimi-K2.6 | 54.0 | 57.7 | +3.7 | ||
| Qwen3.6-27B | 26.0 | 26.3 | +0.3 | ||
| Average | 39.7 | 43.0 | +3.3 |
Analysis
The mechanism analyses indicate that EvoMem is useful when patch history becomes operational: agents retrieve relevant transitions, preserve historical constraints, and recover complete evolving evidence.
On Terminal-Bench-Evo, gains rise from +2.6% to +8.3% when patch uptake is nonzero, showing that historical transition evidence helps most when it changes the agent's plan or commands.
On SWE-Chain-Evo, average PASS_TO_PASS failure rates drop from 9.09% to 6.32%, indicating better preservation of behavior introduced by earlier repository milestones.
On PersonaMem-Evo, temporal trajectory and multi-pattern synthesis questions gain +5.2%, matching the settings where a single consolidated memory state is most likely to lose evidence.
EvoMem improves row-level preference evidence capture from 72.5% to 74.9%, with the largest capture gains on temporal trajectory and multi-pattern synthesis.
Higher token usage does not reliably translate into higher accuracy: Kimi K2.6 and Gemma4-31B-it are strong while using fewer tokens than the cross-model average.
GPT-5.5 has the highest terminal accuracy but uses far more tokens, while Gemini 3.1 Pro and GLM-5.1 remain strong with much lower token budgets.
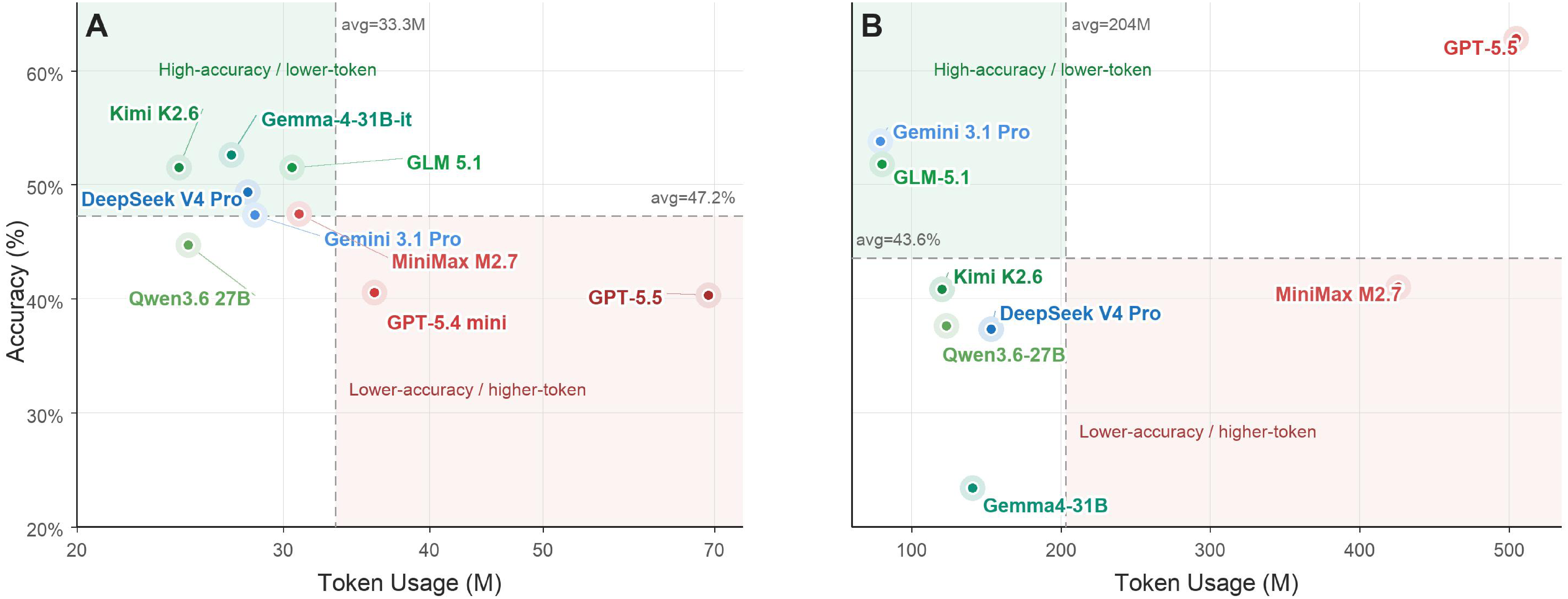
The efficiency analysis shows that token usage is not a reliable proxy for capability. On PersonaMem-Evo, Kimi K2.6 and Gemma4-31B-it reach strong accuracy with below-average token usage, while GPT-5.4-mini and GPT-5.5 consume more tokens without matching their accuracy. On Terminal-Bench-Evo, GPT-5.5 achieves the strongest accuracy but at a much higher token cost, whereas Gemini 3.1 Pro and GLM-5.1 remain competitive with substantially smaller token budgets. This suggests that evolving-agent benchmarks should report accuracy and inference efficiency together.
Citation
@article{xu2026evoarena,
title = {EvoArena: Tracking Memory Evolution for Robust LLM Agents in Dynamic Environments},
author = {Jundong Xu and Qingchuan Li and Jiaying Wu and Yihuai Lan and Shuyue Stella Li and Huichi Zhou and Bowen Jiang and Lei Wang and Jun Wang and Anh Tuan Luu and Caiming Xiong and Hae Won Park and Bryan Hooi and Zhiyuan Hu},
year = {2026},
journal = {arXiv preprint arXiv:2606.13681},
}